
There’s a whole genre of blog post now: a developer explains how they stopped typing most of their code. I’ve read a dozen. They’re true. They’re also all the same story.
This isn’t one of them. I am a solutions architect, but I never stopped being a developer. I design systems, I build them, and I build and train the teams that build them. The three jobs hold together for one reason: I know first-hand what it takes to ship a product. The day I lose that, drawing boxes on a whiteboard stops being direction and becomes decoration.
So when a new kind of builder joined the industry - brilliant, tireless, amnesiac - I did what I do with every new teammate. I worked alongside it. I measured what it could carry. I wrote it an onboarding guide. And these days, I trust it with the night shift.
The strange part: it reads my drawings more carefully than any human teammate ever did.
This post is the first page of a travel journal. I was moved by the best of that genre, Mitchell Hashimoto’s account of his own AI adoption journey - not because his conclusions were surprising, but because he drew a map of stages, and I could point at it and say: I’ve been there. I got stuck there too. So this is my map. Part 1, because the territory is still moving under my feet.
The Ghost in the Editor
It started with Copilot. Gray ghost text, finishing my sentences.
It was seductive in the smallest possible way: it saved keystrokes, not thinking. I accepted suggestions the way you accept spell-check - reflexively, without gratitude. It knew syntax. It did not know intent.
Looking back, this stage taught me almost nothing about working with AI. But it did something sneakier: it normalized the presence of a machine inside my editor. The ghost moved in, and I stopped noticing it was there.
The Editor That Talked Back
Then came Cursor, and two things happened at once.
The first was Tab. Calling it autocomplete undersells it - Copilot finished my sentences; Cursor’s Tab finished my thoughts. I would rename a variable, and the editor would propose the next edit. Then the one after that, three lines down. Then one in another function entirely. Tab, tab, tab - a refactor conducted like an orchestra instead of typed like a memo. It was the first time a tool predicted not what I was writing, but where I was going. Of everything from this era, that feature is the one that deserves the word revolutionary.
The second was the chat moving into the editor. Select a function, ask a question, get an edit. This was the first taste of real delegation - and the first taste of babysitting. The machine could now make changes I didn’t watch happen character by character. Which meant the machine could now make changes I didn’t understand until I read them.
The leash was still short. I was driving line by line, file by file. But something had shifted: I was no longer the only author in the room.
Going All In
Today, my split is roughly 90% Claude, 10% Codex.
Claude does most of the work - and it reviews its own work first. With the newer skill systems (Superpowers and its cousins), self-review stopped being theater: the agent runs its own checklists, hunts its own regressions, and verifies before claiming done. It got genuinely good at grading its own homework.
But self-review is the first gate, never the last. Codex reads everything cold as a second level of review: a model with a different training history, no investment in the choices already made. It catches what the author model is blind to - and what I am too close to see.
One model reviewing itself finds mistakes. A second model finds blind spots.
The deeper change wasn’t the tools. It was the bottleneck. All my career, construction was the slow part: you could design a system faster than anyone could build it. Now construction is nearly free - and the slowest part of building software is describing what to build. For developers, that’s a new job description. For an architect, it’s the old one - suddenly load-bearing.
And for small projects, this was paradise. Whole features in an afternoon. Prototypes before lunch.
Then I pointed the agents at a large system, and hit the wall.
The Wall
Everyone knows by now that agents forget everything between sessions. In 2026 that’s not a secret, it’s onboarding. And every tool ships the same fix: write a context file, and the machine will read it when it wakes up.
I had one, of course. It worked beautifully - right up until the project got big.
Because here’s what the context file becomes on a large system: every rule, every invariant, every warning compressed into one wall of text that only a machine could love. Mine had everything and explained nothing. The agent would read all of it and still miss the one constraint that mattered for today’s task - and I was back to re-explaining the architecture, session after session.
Meanwhile, on the other side of the repo sat my other documentation: deep design specs, one per feature, written at the moment of decision. Precise, dated, already drifting.
Two kinds of documentation, and a stranger could use neither. Nothing in between. No page you could hand to a new engineer - or a new agent - and say: here is the shape of the system. Here is what talks to what, and why.
I suspect your codebase looks the same.
Documentation fails at the altitude problem. Specs are too low - they capture one decision at one point in time, and they rot the day after the merge. Context files are too high - one heroic file that grows until it buries the one rule that mattered today.
The missing layer is the map.
Twelve Questions
I am a visual person. I cannot build what I cannot see. Before any serious implementation, I need to know where we are and where we are going - not as a feeling, but as a picture.
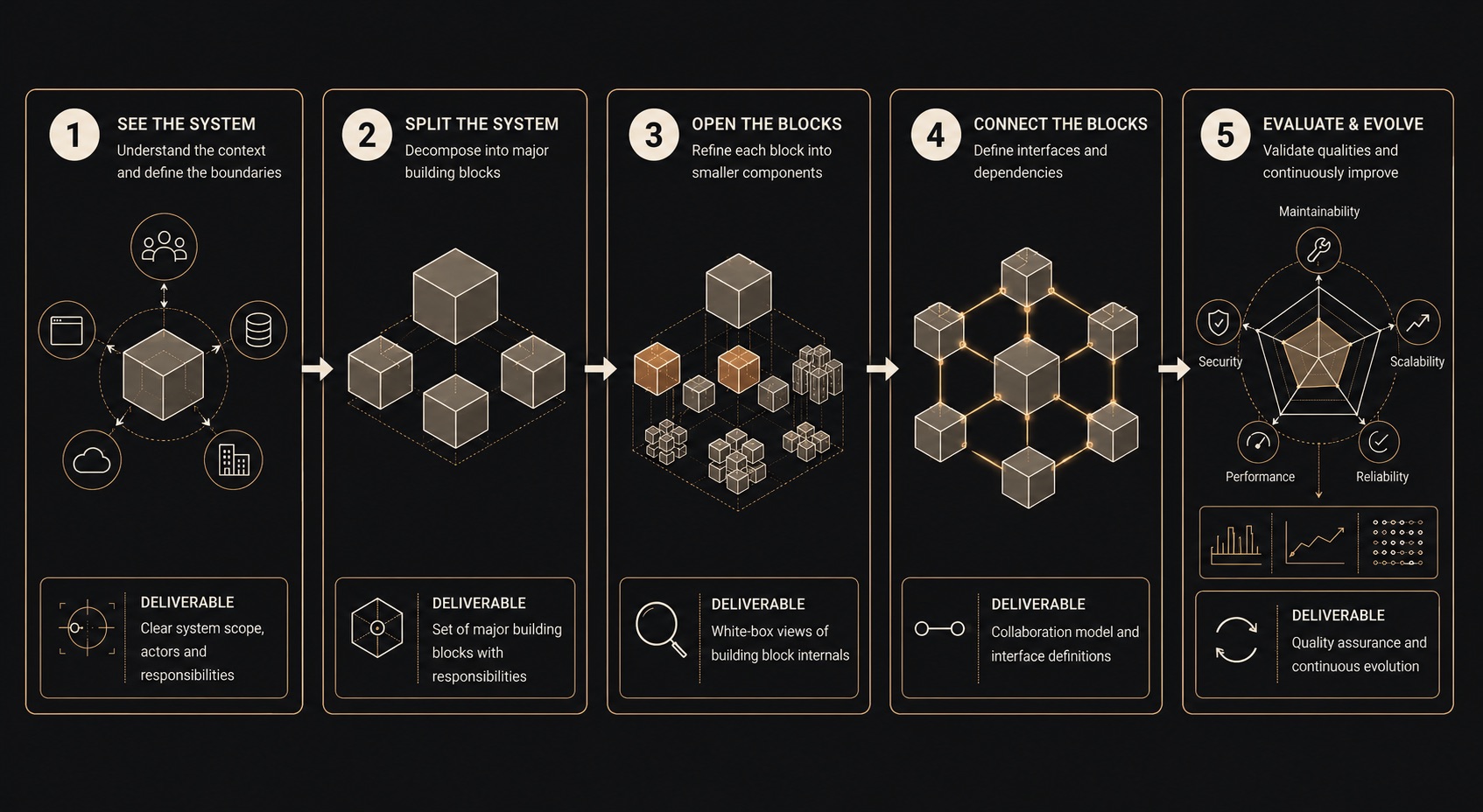
So I went looking for a structure. I tried a few before one stuck - and what follows is not the solution, just the best compromise I’ve found so far for the way I work. It happens to be older than the AI wave: arc42, a template created by Gernot Starke and Peter Hruschka in 2005, back when “the cloud” still meant weather.
Strip away the formal language and arc42 is simply this: the same twelve questions, asked of any software system. What is this for, and who judges whether it’s good? What are we not allowed to change? Who and what does it talk to? What are the big pieces inside? What happens, step by step, when it runs? What decisions did we make along the way, and why? What could go wrong?
Think of the drawing set for a house. An architect never hands the builder a single drawing. They hand over a set: a site plan that shows the house in its street, floor plans that show the rooms, one sheet for electricity, one for plumbing, an elevation that shows the face it turns to the world. Each sheet answers one kind of question. No sheet tries to answer them all. And any builder anywhere can read the set, because the sheets are always the same sheets, in the same order.
That’s arc42. Not a tool. Not a methodology. Nothing to install. A table of contents for understanding a system - the same table of contents, every time. Boring, in the way foundations are boring.
For two decades this was documentation for humans, which meant it was optional. Humans compensate: they ask in the hallway, they read the code, they remember last year’s decisions. Then a new kind of teammate arrived - one that can’t ask in the hallway, and remembers nothing.
Atlas
I borrowed arc42’s bones, bent them to my workflow, and gave the result a name that says what it actually is: Atlas.
An atlas is not one map. It’s a collection of maps at different zoom levels with an index: a world map up front, one page per region, every page drawn to the same legend. You don’t read an atlas cover to cover. You flip to the page you need.
That’s what lives in my repos now. One page per feature. An index that owns the big picture. A fixed template: what it does, where it lives, what it’s made of, what it depends on, and the rules that must never break.
Nothing fancier than a folder of markdown files - docs/atlas/ - living in the repo next to the code it describes. The real atlases belong to client systems, so let me draw the same shape over something everyone knows - imagine a food delivery platform. The index opens like this:
# Feature Atlas
The navigable map of the product's features: what each one does,
what it's made of, and how features depend on each other. One page
per feature; this index owns the big picture. Audience: maintainers
and AI agents who need the system's shape without reading code.
| Feature | Purpose |
|---|---|
| ordering | Take an order from cart to confirmation and keep its immutable record |
| delivery | Assign a courier and track every order to the doorstep |
| rewards | Turn delivered orders into points a customer can spend |
| ... | |And one feature page - each fits on a single screen:
# Rewards - loyalty points engine
## Purpose
Turn delivered orders into points a customer can spend on a later
order: every delivered order earns points based on what was paid,
points expire after a year, and a refund takes back exactly the
points its order once earned.
## At a glance
- **Status:** built (no deferred items)
- **Code:** `server/features/rewards/`
- **Storage:** `reward_ledger` (append-only)
- **HTTP:** `GET /v1/rewards/balance` · `POST /v1/checkout/redeem`
## Subfeatures
| Subfeature | What it is | Status |
|---|---|---|
| Earning rule | Points are credited only when an order reaches "delivered" | built |
| Spending | Points apply as a checkout discount, capped at half the order | built |
| Clawback | A refund reverses exactly the points its order earned | built |
## Depends on
| Feature | Relationship | via |
|---|---|---|
| ordering | A delivered order is the only way points are born | hook: OnOrderDelivered |
## Load-bearing invariants
1. Points are never created without a delivered order.
2. A refund always claws back the points it granted.
3. A balance can never go negative.Every page, same shape. Small enough to fit on one screen, plain enough that anyone in the company could read it, anchored enough that every claim can be checked against the code.
Let me walk through the template, because every section earns its place - and every field exists to answer a question someone, or something, actually asks.
Purpose - one sentence, in business language. What does this feature do for the customer? If the sentence needs a class name to make sense, it gets rewritten. This is the line a new hire reads to decide whether they’re on the right page.
At a glance - the coordinates. Four bullets, always the same four: the status of the feature as a whole, where the code lives, what it stores and where, and the HTTP surface it exposes. When an agent - or a human - needs to jump into a feature, this is the GPS fix. No searching, no guessing.
Subfeatures - what it’s made of. A table of black boxes: name, one-line description, status. The status vocabulary is deliberately tiny - built, partial, deferred, capture-only (the data is recorded, nothing acts on it yet) - because a status is a promise, and vague promises rot. A subfeature stays a single row until it outgrows its one-liner; then it’s promoted to its own page, same template, filed next to its parent, and the row becomes a link.
Depends on / Depended on by - the seams. Two mirrored tables. Each entry leads with a functional sentence - what one feature does for or with the other: a delivered order is the only way points are born. Then, and only then, a via: anchor naming the technical mechanism and the file - the hook, the interface, the bridge. The sentence is for understanding; the anchor is for verification. Headlines for humans, footnotes for auditors.
Load-bearing invariants - the rules that must survive any change. Numbered, blunt, testable. A balance can never go negative is not a description of how the system works; it’s a contract about how it must keep working. When the night shift touches this feature, these are the tripwires.
And one structural rule keeps the whole thing honest: pages stay within one screen, and the index never lists grandchildren. A feature converts to a folder only when it has accumulated several promoted children - not before. The atlas grows the way cities grow: a new district only when the old streets are full.
Here’s the part that changed how I think about authorship: I didn’t write these pages. I edited them.
For each feature, I dispatched a research agent into the code with one instruction: come back with facts, and every fact carries a file and line number. No claims from memory. No “probably.” The agents came back with things I had forgotten about my own system. One feature was fully built, tested, and deployed - and completely absent from my own architecture summary. Another had four consumers where I remembered three.
The agent has no mental model to defend. It reads what is actually there.
But raw research makes terrible documentation. Every wrong turn was caught by a human question. The first draft led every dependency with its technical mechanism - which interface, which file, which hook. I pushed back: a feature map should say “when an order is refunded, the points it earned are taken back.” That sentence needs zero knowledge of the code. We rewrote the admission rule on the spot: a page earns its place by what the system offers, not by how the code is organized.
Notice the division of labor. The agent supplied rigor: parallel research, verified claims, consistency across every page. I supplied taste: what readers need, what’s signal, what’s noise. Neither of us could have produced this alone. That’s not a workflow optimization. That’s a new kind of authorship.
And here’s the loop that makes it durable: the same agent that helped write the atlas now consumes it. When a session starts, it doesn’t re-read the whole system. It loads the index, sees the shape, and pulls the one page it needs. Human and agent, working from a single source of truth - the same map, the same legend.
And not just the agent. A teammate joining from Lagos or Lisbon, a contractor six time zones away, a future me returning after six months - they all open the same atlas and flip to the page they need. Distributed teams have always known what AI just made impossible to ignore: if it isn’t written down somewhere findable, it doesn’t exist.
The maintenance contract is one sentence: if a commit changes a feature’s surface, it updates the feature’s page in the same commit. The pages are small enough that this stays cheap. Curated docs don’t die from lack of tooling. They die because updating them costs more than skipping it.
The Night Shift
The atlas began as archaeology - a map drawn over a system that already existed. But there was a second intention behind it from the start. I had read Anthropic’s engineering guidance on long-running agents before drawing my first page, and it stayed with me. The atlas template is drawn with that harness in sight.
Their recommendation, condensed: break the work into small, testable features with explicit states - that’s the subfeature table, with its built/partial/deferred column. Give the agent a way to know it’s making progress - that’s the invariants, a definition of done sitting at the bottom of every page. Start every session from a known state, work on one feature at a time - that’s a page that fits on one screen. Converting a feature page into an agent’s work plan is not a project. It’s minutes. Anthropic’s researchers ran this shape for days straight and watched Claude compress months of scientific computing into a few days.
The atlas isn’t just documentation agents can read. It’s a work order agents can execute.
So a few evenings a week, I do a version of what Mitchell calls end-of-day agents - except he stops at thirty minutes of queued research before closing the laptop, no overnight loops. I go further, because the atlas changed the risk. I pick a feature page, break its deferred rows into tasks, and hand the list to an agent running in a Ralph loop - the community’s name for the dumbest harness that works: feed the agent its task file, let it work until its context fills, then feed it the same file again. Fresh eyes every iteration; the repo, the git history, and the atlas are the memory. Hours of work, broken down at dusk, burned down by dawn.
Some mornings I open the diffs and it’s Christmas. Some mornings the night crew misread a drawing, and the review becomes a lesson - usually a sentence that was missing from the page. Either way, the status column moved, and the atlas got sharper.
And that completes the reversal. The atlas is not just for reverse-engineering systems that already exist. On new projects, I now draw it first - an index and a stack of pages where every status reads “deferred” - and let the system grow into its map. Which is the only direction architects ever drew: nobody blueprints a house after it’s built.
The Honest Reckoning
I won’t pretend this is solved.
The same-commit contract is young. Hand-curated documentation has a failure rate, and mine has not yet survived a deadline crunch. Ask me in six months whether it held.
There’s a cost I didn’t expect: writing honest pages surfaced deferred work and known gaps that were comfortable staying vague. An atlas with a “deferred” column is a commitment device. Every page now quietly asks: so when?
The agents were also only as good as the architecture let them be. My system forces cross-feature dependencies through named seams, so dependencies were findable. In a codebase where everything imports everything, the research agents would have come back with mud. The map can only be as honest as the territory.
And there’s the question I sit with most: what am I losing? My hands type less code every month. Anthropic ran a controlled trial on exactly this fear: engineers who delegated code generation to AI scored 17% lower on comprehension tests than those who coded by hand. The productivity gains didn’t even reach statistical significance.
But buried in the same study is a nuance I hold onto. Participants who used AI to ask conceptual questions - to understand before building - scored above 65%. Pure delegators scored below 40%. The difference between losing a skill and changing a skill is whether you keep asking why.
I review more than I write now - and reviewing is a skill that was built by years of writing. I don’t know yet what happens to the engineers who start from the review side.
Still Drawing
We started all of this to write documentation for a machine - context for an agent that forgets everything between sessions.
But everything that makes documentation good for an agent - small pages, one purpose each, claims you can verify, an index instead of a narrative - is what made documentation good for people all along. We just never had a reader demanding enough to force us to do it.
The machine didn’t need better docs than humans do. It just refused to pretend the bad ones were fine.
This is where I am today. Part 1, not because I know how many parts there will be, but because I know this isn’t the last one. The territory is moving, and the map has to move with it.
I’m still drawing it.